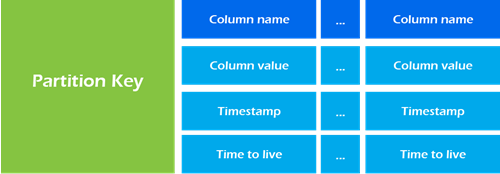
Data Model
Map<RowKey, SortedMap<ColumnKey, ColumnValue>>

CREATE KEYSPACE sports
WITH REPLICATION = {'class' : 'NetworkTopologyStrategy', 'datacenter1' : 2};
# you can tune the r/w consistency level with keyspace Availability versus Consistency
CREATE TABLE crossfit_gyms_by_city (
country_code text,
state_province text,
city text,
gym_name text,
opening_date timestamp,
PRIMARY KEY ((country_code, state_province, city), opening_date, gym_name)
) WITH CLUSTERING ORDER BY ( opening_data ASC, gym_name ASC );
| Cassandra | RDBMS |
|---|---|
| Keyspace | Database |
| Column Family | Table |
| Partition Key | Primary Key |
Partitioner
A partitioner determines how data is distributed across the nodes in the cluster (including replicas).
- Murmur3Partitioner (default): uniformly distributes data across the cluster based on MurmurHash hash values.
- RandomPartitioner: uniformly distributes data across the cluster based on MD5 hash values.
- ByteOrderedPartitioner: keeps an ordered distribution of data lexically by key bytes

R/W

To satisfy a read, Cassandra must combine results from the active memtable and potentially multiple SSTables. Cassandra processes data at several stages on the read path to discover where the data is stored, starting with the data in the memtable and finishing with SSTables:
- Check the memtable
- Check row cache, if enabled
- Checks Bloom filter
- Checks partition key cache, if enabled
- Goes directly to the compression offset map if a partition key is found in the partition key cache, or checks the partition summary if not If the partition summary is checked, then the partition index is accessed
- Locates the data on disk using the compression offset map
- Fetches the data from the SSTable on disk

- Logging data in the commit log
- Writing data to the memtable
- Flushing data from the memtable
- Storing data on disk in SSTables
Limits
- No join or subquery support for aggregation. According to Cassandra’s documentation, this is by design, encouraging denormalization of data into partitions that can be queried efficiently from a single node, rather than gathering data from across the entire cluster.
- Ordering is set at table creation time on a per-partition basis. This avoids clients attempting to sort billions of rows at run time.
- All data for a single partition must fit on disk in a single node in the cluster.
- It’s recommended to keep the number of rows within a partition below 100,000 items and the disk size under 100 MB.
- A single column value is limited to 2 GB (1 MB is recommended).
Connect
from cassandra.cluster import Cluster
from cassandra.auth import PlainTextAuthProvider
auth_provider = PlainTextAuthProvider(
username='cassandra', password='cassandra')
cluster = Cluster(auth_provider=auth_provider)
session = cluster.connect()
session.execute("Your CQL")
Docker Cluster
docker-composer.yaml
# Please note we are using Docker Compose version 3
version: '3'
services:
# Configuration for our seed cassandra node. The node is call DC1N1
# .i.e Node 1 in Data center 1.
DC1N1:
# Cassandra image for Cassandra version 3.1.0. This is pulled
# from the docker store.
image: cassandra:3.11
# In case this is the first time starting up cassandra we need to ensure
# that all nodes do not start up at the same time. Cassandra has a
# 2 minute rule i.e. 2 minutes between each node boot up. Booting up
# nodes simultaneously is a mistake. This only needs to happen the firt
# time we bootup. Configuration below assumes if the Cassandra data
# directory is empty it means that we are starting up for the first
# time.
command: bash -c 'if [ -z "$$(ls -A /var/lib/cassandra/)" ] ; then sleep 0; fi && /docker-entrypoint.sh cassandra -f'
# Network for the nodes to communicate
networks:
- dc1ring
ports:
- "9041:9042"
# Maps cassandra data to a local folder. This preserves data across
# container restarts. Note a folder n1data get created locally
volumes:
- ./n1data:/var/lib/cassandra
# Docker constainer environment variable. We are using the
# CASSANDRA_CLUSTER_NAME to name the cluster. This needs to be the same
# across clusters. We are also declaring that DC1N1 is a seed node.
environment:
- CASSANDRA_CLUSTER_NAME=dev_cluster
- CASSANDRA_SEEDS=DC1N1
# Exposing ports for inter cluste communication
expose:
- 7000
- 7001
- 7199
- 9042
- 9160
# Cassandra ulimt recommended settings
ulimits:
memlock: -1
nproc: 32768
nofile: 100000
# This is configuration for our non seed cassandra node. The node is call
# DC1N1 .i.e Node 2 in Data center 1.
DC1N2:
# Cassandra image for Cassandra version 3.1.0. This is pulled
# from the docker store.
image: cassandra:3.11
# In case this is the first time starting up cassandra we need to ensure
# that all nodes do not start up at the same time. Cassandra has a
# 2 minute rule i.e. 2 minutes between each node boot up. Booting up
# nodes simultaneously is a mistake. This only needs to happen the firt
# time we bootup. Configuration below assumes if the Cassandra data
# directory is empty it means that we are starting up for the first
# time.
command: bash -c 'if [ -z "$$(ls -A /var/lib/cassandra/)" ] ; then sleep 60; fi && /docker-entrypoint.sh cassandra -f'
# Network for the nodes to communicate
networks:
- dc1ring
ports:
- "9042:9042"
# Maps cassandra data to a local folder. This preserves data across
# container restarts. Note a folder n1data get created locally
volumes:
- ./n2data:/var/lib/cassandra
# Docker constainer environment variable. We are using the
# CASSANDRA_CLUSTER_NAME to name the cluster. This needs to be the same
# across clusters. We are also declaring that DC1N1 is a seed node.
environment:
- CASSANDRA_CLUSTER_NAME=dev_cluster
- CASSANDRA_SEEDS=DC1N1
# Since DC1N1 is the seed node
depends_on:
- DC1N1
# Exposing ports for inter cluste communication. Note this is already
# done by the docker file. Just being explict about it.
expose:
# Intra-node communication
- 7000
# TLS intra-node communication
- 7001
# JMX
- 7199
# CQL
- 9042
# Thrift service
- 9160
# Cassandra ulimt recommended settings
ulimits:
memlock: -1
nproc: 32768
nofile: 100000
# This is configuration for our non seed cassandra node. The node is call
# DC1N3 .i.e Node 3 in Data center 1.
DC1N3:
image: cassandra:3.11
# In case this is the first time starting up cassandra we need to ensure
# that all nodes do not start up at the same time. Cassandra has a
# 2 minute rule i.e. 2 minutes between each node boot up. Booting up
# nodes simultaneously is a mistake. This only needs to happen the firt
# time we bootup. Configuration below assumes if the Cassandra data
# directory is empty it means that we are starting up for the first
# time.
command: bash -c 'if [ -z "$$(ls -A /var/lib/cassandra/)" ] ; then sleep 120; fi && /docker-entrypoint.sh cassandra -f'
# Network for the nodes to communicate. This is pulled from docker hub.
ports:
- "9043:9042"
networks:
- dc1ring
# Maps cassandra data to a local folder. This preserves data across
# container restarts. Note a folder n1data get created locally
volumes:
- ./n3data:/var/lib/cassandra
# Docker constainer environment variable. We are using the
# CASSANDRA_CLUSTER_NAME to name the cluster. This needs to be the same
# across clusters. We are also declaring that DC1N1 is a seed node.
environment:
- CASSANDRA_CLUSTER_NAME= dev_cluster
- CASSANDRA_SEEDS=DC1N1
# Since DC1N1 is the seed node
depends_on:
- DC1N1
# Exposing ports for inter cluste communication. Note this is already
# done by the docker file. Just being explict about it.
expose:
# Intra-node communication
- 7000
# TLS intra-node communication
- 7001
# JMX
- 7199
# CQL
- 9042
# Thrift service
- 9160
# Cassandra ulimt recommended settings
ulimits:
memlock: -1
nproc: 32768
nofile: 100000
# A web based interface for managing your docker containers.
portainer:
image: portainer/portainer
command: --templates http://templates/templates.json
networks:
- dc1ring
volumes:
- /var/run/docker.sock:/var/run/docker.sock
- ./portainer-data:/data
# Enable you to access potainers web interface from your host machine
# using http://localhost:10001
ports:
- "10001:9000"
networks:
dc1ring:
Records
cluster logs and folder structure

connect to cassandra using python driver

Reference
- https://shermandigital.com/blog/designing-a-cassandra-data-model/
- http://abiasforaction.net/apache-cassandra-cluster-docker/
- http://abiasforaction.net/a-practical-introduction-to-cassandra-query-language/
- https://hub.docker.com/_/cassandra/
- https://academy.datastax.com/resources/getting-started-time-series-data-modeling
- https://academy.datastax.com/resources/getting-started-time-series-data-modeling
- https://pandaforme.gitbooks.io/introduction-to-cassandra/content/understand_the_cassandra_data_model.html